









はじめに
Pythonでのテーブルデータ処理のライブラリとして、最近、処理が高速等の理由からPolarsが流行っているような印象があります。勉強のためにもPandasで行っていた処理をPolarsに移行しようと思いました。
Excel読み込みのオプション(sheet_name, sheet_id, skip_rowの指定)と、Excelのシート名の取得がすぐにわからなかったので、下記で試しながら比較していきます。
PolarsでExcel読み込みとシート名の取得
リファレンス、参考にさせていただいたサイト
- pola-rs/polars: Dataframes powered by a multithreaded, vectorized query engine, written in Rust (github.com)
- Index – Polars user guide
- 超高速…だけじゃない!Pandasに代えてPolarsを使いたい理由 #Python – Qiita
- pandasから移行する人向け polars使用ガイド #Python – Qiita
用意したExcelファイル
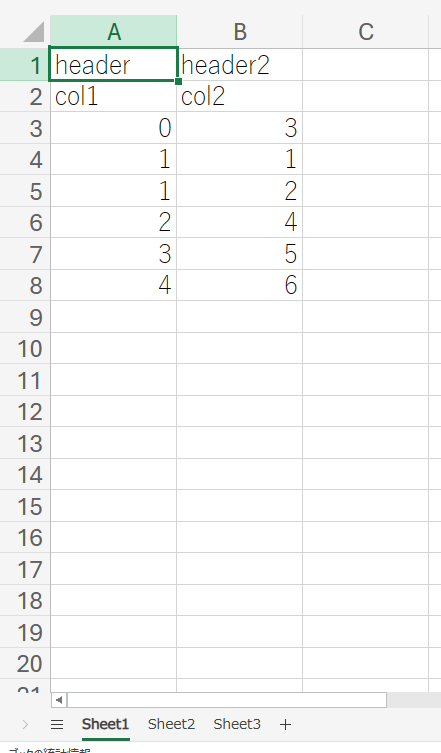
まず、用意したExcelファイルを下記に示します。
シートは3つ含まれています。Sheet1は、邪魔な行が1行あり、その後にcol1, col2というHeader行がある想定です。
- Sheet1
- Sheet2
- Sheet3
1) Excel読み込み(sheet_nameとsheet_id)
1-1) 引数にパスだけ指定した場合
コード
def get_args() -> argparse.Namespace:
# 略 コード全体を参照
def main() -> None:
args = get_args()
path = args.excel_file
# --- 1-1) Excelファイルの読み込み
excel_data = pl.read_excel(
source=path,
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
if __name__ == "__main__":
main()
出力
<class 'polars.dataframe.frame.DataFrame'>
shape: (7, 2)
┌────────┬─────────┐
│ header ┆ header2 │
│ --- ┆ --- │
│ str ┆ str │
╞════════╪═════════╡
│ col1 ┆ col2 │
│ 0 ┆ 3 │
│ 1 ┆ 1 │
│ 1 ┆ 2 │
│ 2 ┆ 4 │
│ 3 ┆ 5 │
│ 4 ┆ 6 │
└────────┴─────────┘デフォルトでは、1つ目のシート(Sheet1)が読み込まれるようです。返ってくる型は、DataFrameです。
1-2) sheet_id 引数
コード
def get_args() -> argparse.Namespace:
# 略 コード全体を参照
def main() -> None:
args = get_args()
path = args.excel_file
# --- 1-2) sheet_id 引数
excel_data = pl.read_excel(
source=path,
sheet_id=1,
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
if __name__ == "__main__":
main()
出力
<class 'polars.dataframe.frame.DataFrame'>
shape: (7, 2)
┌────────┬─────────┐
│ header ┆ header2 │
│ --- ┆ --- │
│ str ┆ str │
╞════════╪═════════╡
│ col1 ┆ col2 │
│ 0 ┆ 3 │
│ 1 ┆ 1 │
│ 1 ┆ 2 │
│ 2 ┆ 4 │
│ 3 ┆ 5 │
│ 4 ┆ 6 │
└────────┴─────────┘sheet_id引数を1に指定しました。この場合、返ってくるのはSheet1のDataFrameです。1-1)と同じですね。
1-3) sheet_name 引数
コード
def get_args() -> argparse.Namespace:
# 略 コード全体を参照
def main() -> None:
args = get_args()
path = args.excel_file
# --- 1-3) sheet_name 引数
excel_data = pl.read_excel(
source=path,
sheet_name="Sheet1",
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
if __name__ == "__main__":
main()
出力
<class 'polars.dataframe.frame.DataFrame'>
shape: (7, 2)
┌────────┬─────────┐
│ header ┆ header2 │
│ --- ┆ --- │
│ str ┆ str │
╞════════╪═════════╡
│ col1 ┆ col2 │
│ 0 ┆ 3 │
│ 1 ┆ 1 │
│ 1 ┆ 2 │
│ 2 ┆ 4 │
│ 3 ┆ 5 │
│ 4 ┆ 6 │
└────────┴─────────┘sheet_name引数を”Sheet1″に指定しました。この場合も返ってくるのはSheet1のDataFrameです。1-1),1-2)と同じです。
2) Excelファイルのシート名の取得
シートを指定して、Excelファイルを読み込む方法はわかりました。では、例えばExcelファイルを読み込んで、シート名をコンソールに出力し、ユーザーに選んでもらう場合など、プログラム内部でシート名を扱いたい場合は、シート名を取得する必要があります。どうすればよいでしょうか。
調べてもすぐにわからなかったので、こちらにまとめておきます。
コード
def get_args() -> argparse.Namespace:
# 略 コード全体を参照
def main() -> None:
args = get_args()
path = args.excel_file
# --- 2) シート名の取得
excel_data = pl.read_excel(path, sheet_id=0)
print(type(excel_data))
# -> <class 'dict'>
print(excel_data)
# -> 出力参照
print(excel_data.keys())
# -> dict_keys(['Sheet1', 'Sheet2', 'Sheet3'])
if __name__ == "__main__":
main()
出力(Sheetごとのデータの中身は意味がないので、無視してください)
<class 'dict'>
{'Sheet1': shape: (7, 2)
┌────────┬─────────┐
│ header ┆ header2 │
│ --- ┆ --- │
│ str ┆ str │
╞════════╪═════════╡
│ col1 ┆ col2 │
│ 0 ┆ 3 │
│ 1 ┆ 1 │
│ 1 ┆ 2 │
│ 2 ┆ 4 │
│ 3 ┆ 5 │
│ 4 ┆ 6 │
└────────┴─────────┘, 'Sheet2': shape: (2, 2)
┌──────┬───────────────┐
│ bbb ┆ _duplicated_0 │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞══════╪═══════════════╡
│ 44 ┆ null │
│ null ┆ 555 │
└──────┴───────────────┘, 'Sheet3': shape: (1, 2)
┌───────┬───────────────┐
│ ccccc ┆ _duplicated_2 │
│ --- ┆ --- │
│ str ┆ i64 │
╞═══════╪═══════════════╡
│ null ┆ 888 │
└───────┴───────────────┘}
dict_keys(['Sheet1', 'Sheet2', 'Sheet3'])sheet_id=0として読み込むと、全てのSheetの情報が入ったdict型で返ってくるようです。
このdictのkeyを取得することにより、シート名を取得できます。
3) Excel読み込み(skip_row)
3-1) “skip_rows”: 0
コード
下記のコードでは、Sheet1を読み込み、行方向の読み込みスキップなしとしています。
Polarsでは、read_options={"skip_rows": 0}, として行スキップを指定するようです。
def get_args() -> argparse.Namespace:
# 略 コード全体を参照
def main() -> None:
args = get_args()
path = args.excel_file
# --- 3-1) skip_row
excel_data = pl.read_excel(
source=path,
sheet_id=1,
read_options={"skip_rows": 0},
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
if __name__ == "__main__":
main()
出力
<class 'polars.dataframe.frame.DataFrame'>
shape: (7, 2)
┌────────┬─────────┐
│ header ┆ header2 │
│ --- ┆ --- │
│ str ┆ str │
╞════════╪═════════╡
│ col1 ┆ col2 │
│ 0 ┆ 3 │
│ 1 ┆ 1 │
│ 1 ┆ 2 │
│ 2 ┆ 4 │
│ 3 ┆ 5 │
│ 4 ┆ 6 │
└────────┴─────────┘出力は、デフォルト時と同じになります。この場合、邪魔な行もDataFrameに読み込まれてしまっています。
3-2) “skip_rows”: 1
コード
下記のコードでは、Sheet1を読み込み、最初の行の読み込みをスキップする read_options={"skip_rows": 1}, としています。
def get_args() -> argparse.Namespace:
# 略 コード全体を参照
def main() -> None:
args = get_args()
path = args.excel_file
# --- 3-2) skip_row
excel_data = pl.read_excel(
source=path,
sheet_id=1,
read_options={"skip_rows": 1},
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
if __name__ == "__main__":
main()
出力
<class 'polars.dataframe.frame.DataFrame'>
shape: (6, 2)
┌──────┬──────┐
│ col1 ┆ col2 │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞══════╪══════╡
│ 0 ┆ 3 │
│ 1 ┆ 1 │
│ 1 ┆ 2 │
│ 2 ┆ 4 │
│ 3 ┆ 5 │
│ 4 ┆ 6 │
└──────┴──────┘期待通りの出力となりました。
邪魔な1行目はスキップされ、DataFrameのデータの部分には数値データのみとなっています。
コード全体
argparseでコマンドラインからExcelファイルパスを取得し、ファイルの読み込みを行っています。
Usage
python trial_polars.py -f test.xlsxコード全体
import argparse
import polars as pl
# --- !!! Excel処理とは無関係 コマンドライン引数の処理
def get_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(description="Read Excel file")
parser.add_argument(
"-f",
"--excel_file",
type=str,
required=True,
help="Path to the Excel file",
)
args = parser.parse_args()
return args
def main() -> None:
args = get_args()
path = args.excel_file
# --- 1-1) Excelファイルの読み込み
excel_data = pl.read_excel(
source=path,
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
# --- 1-2) sheet_id 引数
excel_data = pl.read_excel(
source=path,
sheet_id=1,
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
# --- 1-3) sheet_name 引数
excel_data = pl.read_excel(
source=path,
sheet_name="Sheet1",
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
# --- 2) シート名の取得
excel_data = pl.read_excel(path, sheet_id=0)
print(type(excel_data))
# -> <class 'dict'>
print(excel_data)
# -> 出力参照
print(excel_data.keys())
# -> dict_keys(['Sheet1', 'Sheet2', 'Sheet3'])
# --- 3-1) skip_row
excel_data = pl.read_excel(
source=path,
sheet_id=1,
read_options={"skip_rows": 0},
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
# --- 3-2) skip_row
excel_data = pl.read_excel(
source=path,
sheet_id=1,
read_options={"skip_rows": 1},
)
print(type(excel_data))
# -> <class 'polars.dataframe.frame.DataFrame'>
print(excel_data)
# -> 出力参照
if __name__ == "__main__":
main()
おわりに
リファレンスをちゃんと読めば書いてあったのかと思いますが、Web検索やChatGPTの返答でもシート名の取得等はすぐに分からなかったので、メモとして残しました。

コメント